
 By Dylan Murphy, VP of Product Management at Ocient
By Dylan Murphy, VP of Product Management at Ocient
When Ocient emerged from stealth mode in 2022, we brought to market a new kind of data warehouse that is capable of analyzing the world’s largest datasets. With all the best intentions, we have partnered and learned from customers in data rich industries including telco, adtech and more to marry cutting edge hardware with best in class software to deliver previously infeasible capabilities, like querying trillions of rows of complex data types in interactive time or, put more simply, seconds. But with a focus on what we call “hyperscale,” we were quickly reminded that not all data and AI challenges are defined by the volume of the data being analyzed. We still get asked, “What do you mean by hyperscale?” or “How do I know if I need a hyperscale data solution?”
Further down in this post, I’ll share my answer to those questions and break down common scenarios we categorize as hyperscale data challenges that Ocient solves. In each, Ocient’s Compute Adjacent Storage Architecture™ (CASA) brings the ability to effectively boost performance and efficiently analyze datasets that many had written off as being too large or too complex to be useful at any reasonable cost.
Before we look at Ocient’s approach, let’s take a look back at the recent history of data warehouses and the unrelenting pace of innovation since the late 2000s.
The Rise of Cloud Data Warehouses: Innovation with Elasticity
When Amazon Redshift entered the market in 2013, the landscape of data warehouses was largely comprised of:
- On premises data warehouses – typically analyzing small volumes of data quickly. Example technologies include those released by familiar large enterprises like Oracle and Microsoft, as well as other providers with well-established relationships with customers.
- Hadoop-based databases – capable of storing massive volumes of data cost effectively, but with slow query response times. The power of Hadoop and Postgres-based databases brought a renewed optimism to data engineering teams looking to modernize their tech stacks.
- Homegrown systems – early leaders like Facebook (now Meta) and Yahoo with well-resourced engineering teams reinvented data analysis and took leadership positions with their own proprietary technical stacks.
But it was the elasticity of cloud environments that changed the game. The success of Redshift and subsequent cloud data warehouses like Snowflake enabled businesses to spin up analytics environments in the cloud, where they could quickly analyze small subsets of data pulled from massive volume stores.
One of the big architectural innovations introduced with cloud data warehouses was the separation of compute from storage. With the two decoupled, users could leverage low cost data storage, such as an Amazon S3 bucket, while executing quick data analysis on a separate compute tier.
In a cloud data warehouse like Snowflake, historical data is typically kept in a remote object store and can be pulled in across a network connection when needed. We refer to this cloud data warehouse architecture, where a limited amount of data is kept “hot” or fresh in memory while the majority of data is stored remotely for access as needed, as Remote Object Storage Architecture (ROSA). Moving data through the network tier introduces latency and cost, but when there’s not a lot of need to access the remote data, the elasticity often outweighs the drawbacks or cost implications of storing a high volume of data remotely.
Common Workload Characteristics for Cloud Data Warehouses
Cloud data warehouses – and later, lakehouses – filled a gap in the market by providing easy access to slices of data in an elastic fashion where spinning up (and down) resources to create reports and run jobs enables organizations to save on precious cloud computing resources.
For these workloads, we typically see the following attributes:
- The value of data decreases over time
- Data volumes grow over time but only subsets are actionable
- Query latency reduces over time
- Data accessed reduces over time
The Forrester chart below shows how the value of data analysis decreases over time, even as data volume grows.
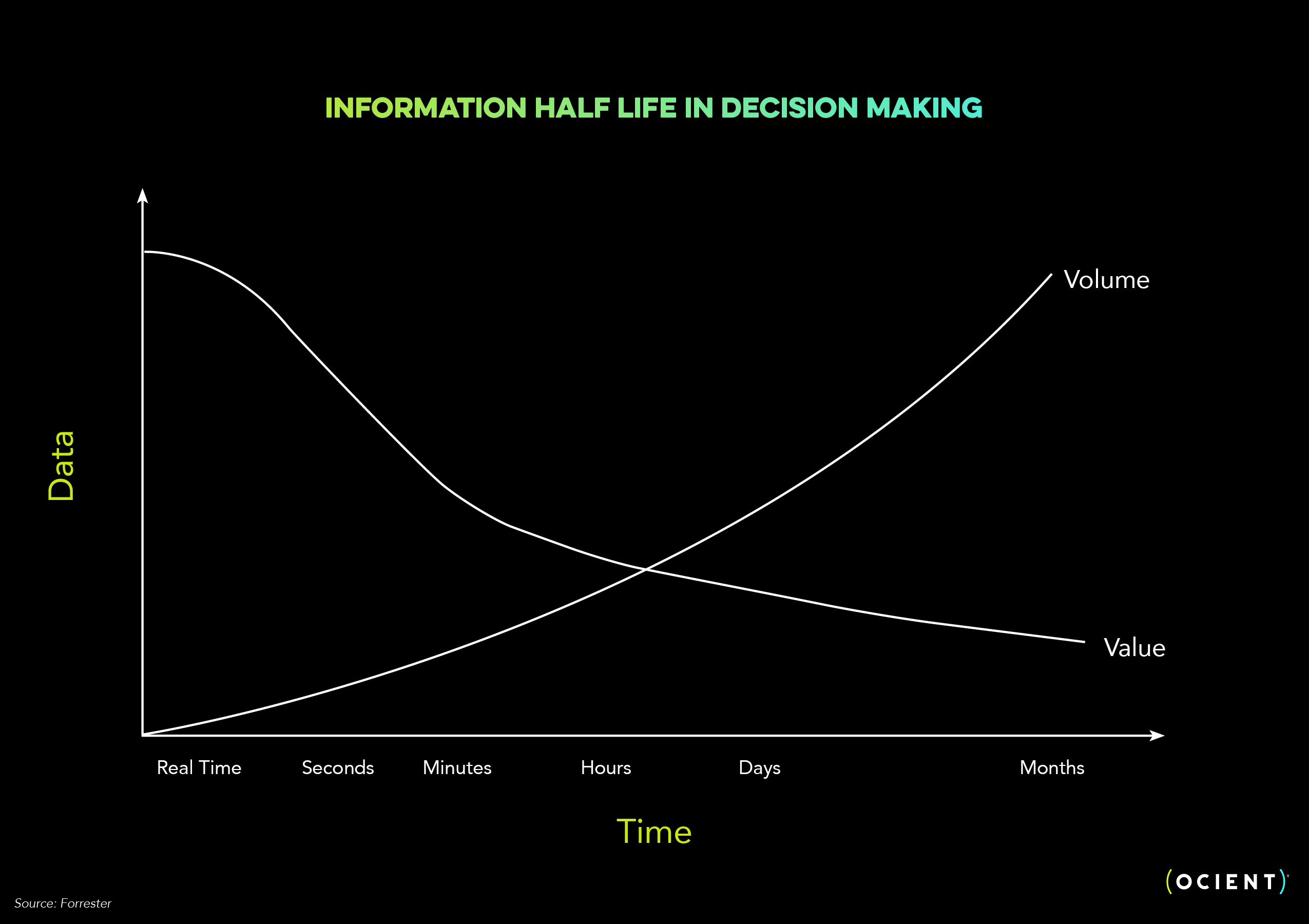
ROSA cloud data warehouses work well for these workloads because:
- The volume of data that requires interactive response times (e.g., sub-second to seconds) is often low.
- Moving historical data in and out of the compute tier does not introduce challenges because the query latency requirements for this type of data are low.
We see several solutions in the market tackling these types of workloads for a small to moderate size of data. This is not the market challenge Ocient is tackling.
The true meaning behind “hyperscale”
As mentioned earlier, the foundational feature of our product is a Compute Adjacent Storage Architecture (CASA) which moves compute closer to storage. While we initially thought the requirements for hyperscale data analytics would involve the world’s largest data sets, what we’ve found in talking with customers are four common situations in which CASA provides a cost-effective and performance-enhancing solution that clearly outshines a typical cloud data warehouse. Let’s take a closer look at some specific workload patterns where CASA is at its best.
Workload Pattern #1: Consolidating multiple workloads into a single data management solution
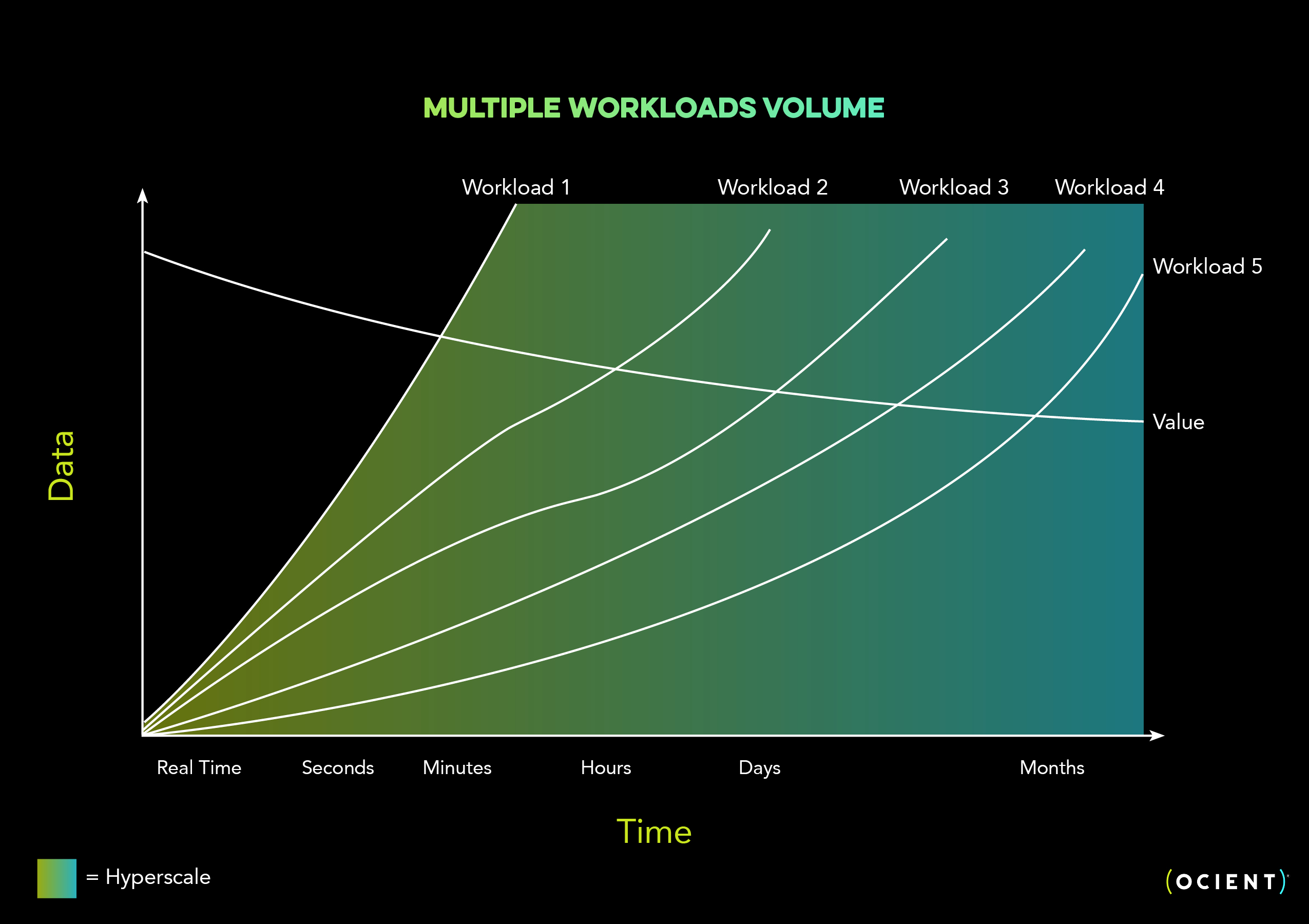
Ocient excels at use cases where customers value streamlining their time and resources by consolidating multiple complex workloads for a particular use case or business need into one system. In these cases, the individual workloads may not be hundreds of terabytes to petabytes of data, but as they multiply, you quickly get into hyperscale data analytics.
Where we see this most commonly is around consolidating workloads and functionality tied to a given set of data that has become unruly. Nevermind looking across an entire data stack — even consolidating systems on a single challenging use case brings efficiency and value where data teams in the past may have struggled to maintain systems.
What the chart below shows is that when consolidating smaller workloads on top of each other in a single system, the volume of the data grows while its value remains relatively constant. Here, delivering complex analysis in a single system with multiple workloads quickly starts looking like a hyperscale requirement
Workload Pattern #2: Growing timeframe for valuable data within a single workload
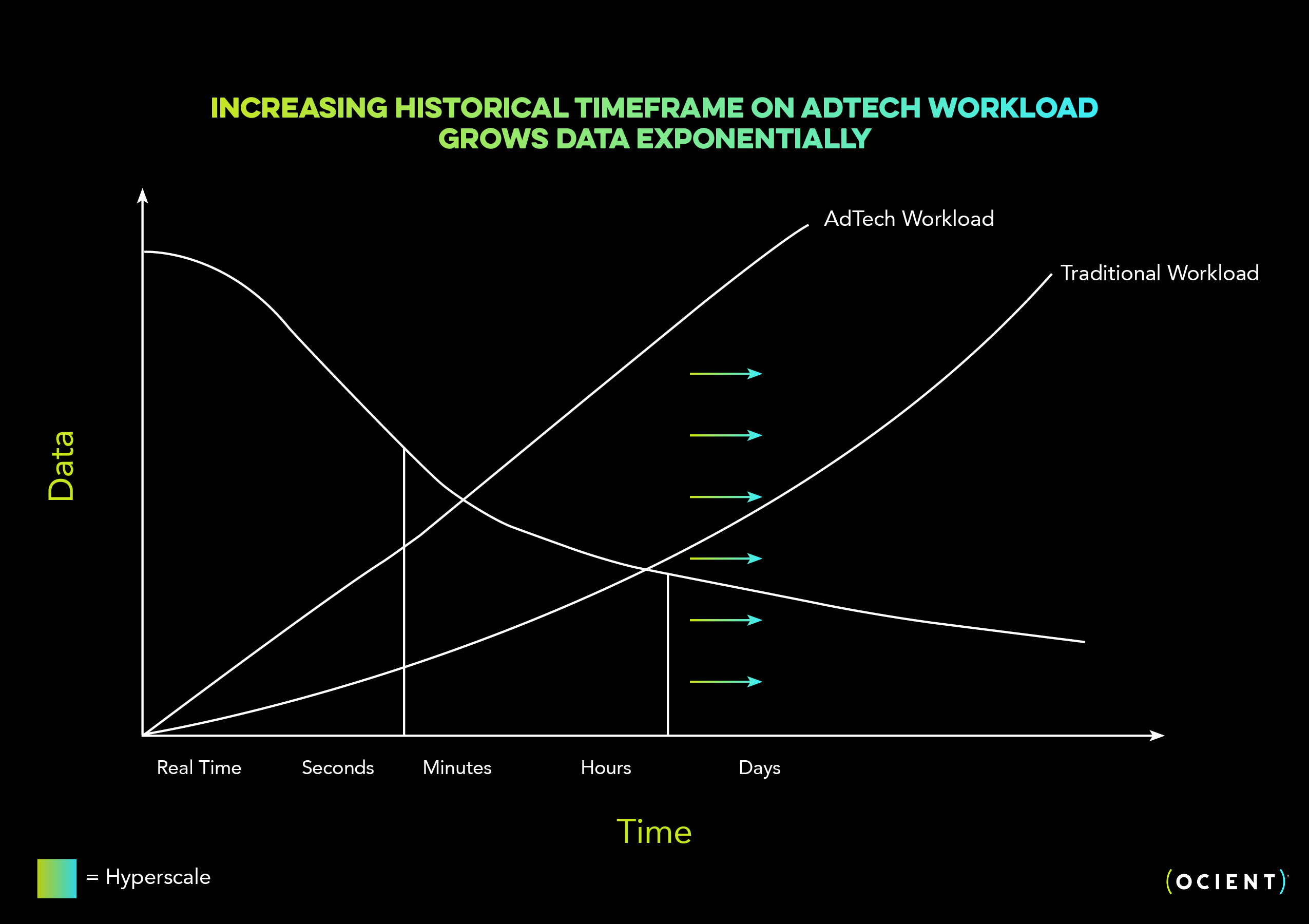
Another pattern we’re seeing with customers is a growth in the timeframe for when data is most valuable. Our AdTech customers face this challenge – in their industry, data volume grows more rapidly than average. While the overall timeframe for their data analysis is still relatively short (e.g., days rather than months or years), any increase in this timeframe results in mountains more data, and it becomes too costly or purely infeasible to analyze using open source or cloud data warehouse solutions. In this situation, a single workload becomes hyperscale in nature.
Within this type of workload, data must be kept “hot” or accessible for days. Sending it to a remote object store would introduce latency and cost that could be detrimental to the user’s ability to deliver value for their organization or enterprise.
Below you can see that with any increase in time (shown by the arrows pointing to the right), the data to be analyzed grows exponentially.
Workload Pattern #3: Scaling ELT to the point of hyperscale
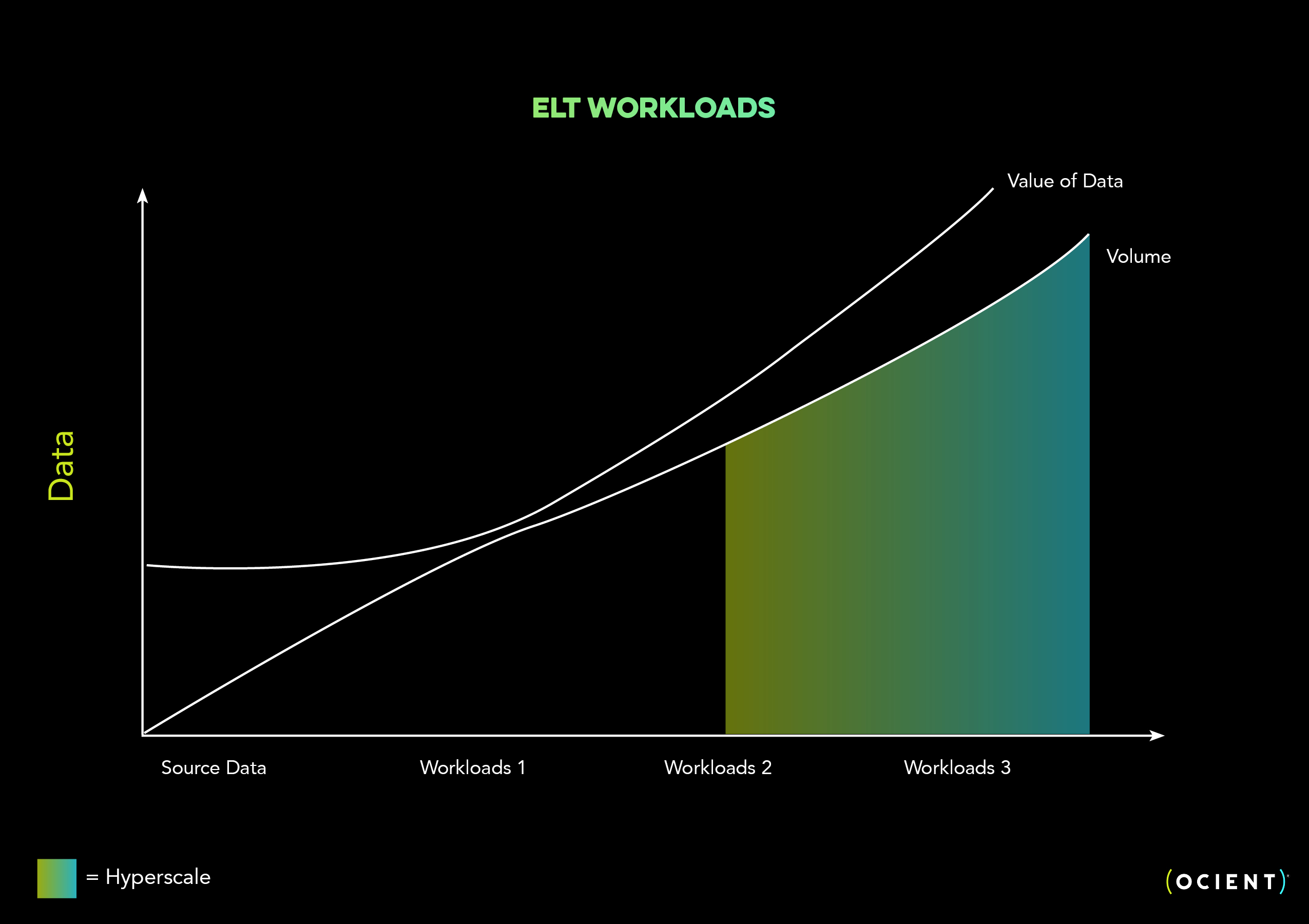
For many of our customers, extract, load, transform (ELT) workloads start small, but additional workflows and iteration create massive intermediate datasets. Although their starting point isn’t hyperscale, these types of workloads often become hyperscale due to the level of data processing required from source data to deliverable.
Analyzing any size dataset starts with loading it efficiently and unifying ELT processes that increasingly must account for complex data types. Packing more data into an ELT process can lead to more valuable data products and results, but as the scale of data and intermediate processing grows, a workload can become hyperscale. For this workload pattern, the value of data grows through the ELT process, peaking when the data deliverable is in its final state.
Workload Pattern #4: Increasing data processing for highly complex data types within the “valuable” time frame
Not all data sets are created equal. For more complex data types, increasing the volume of data analyzed may add disproportionate requirements to the level of computational power utilized to execute that workload.
We see this most commonly with geospatial workloads, where the volume and processing needed to ingest, transform, and analyze data within the “valuable” time frame quickly shift the workload into hyperscale territory. Many of our OcientGeo™ customers were simply not ingesting or analyzing their spatiotemporal datasets due to infeasibility, cost, or both.
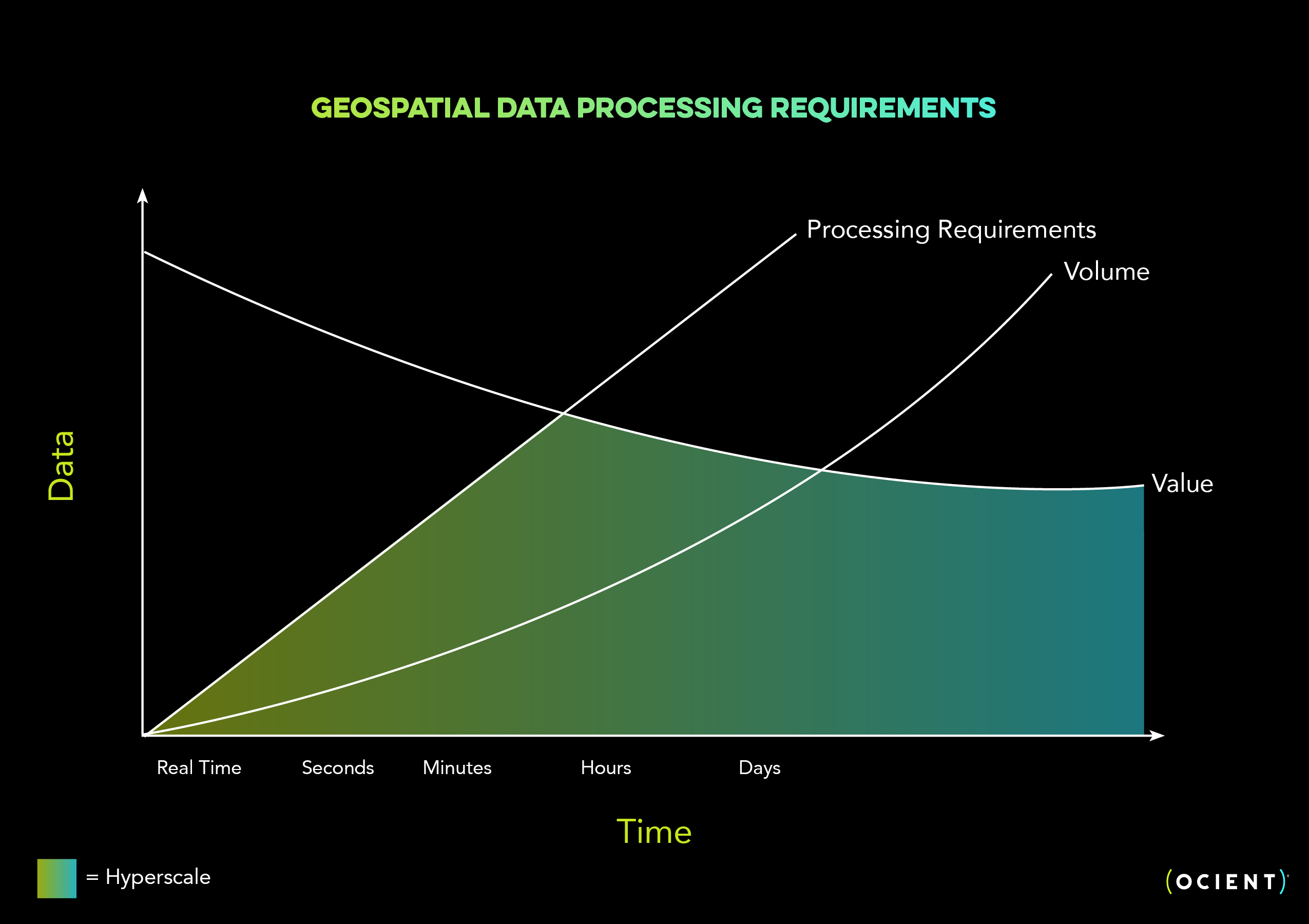
The processing requirements on complex data types and analytics grows quickly with a growing volume of data.
When complex data types and analytics grow, the processing requirements can quickly cross into hyperscale. Even if the data is only valuable within a short timeframe, you could be at hyperscale when you pair the processing complexity and the volume (as demonstrated in the chart above – processing complexity and volume together to make up hyperscale data analytics requirements).
Where cloud data warehouses would struggle or quickly balloon costs, hyperscale data analytics systems like Ocient deliver the time and space intelligence required to derive more value from spatial, time series data.
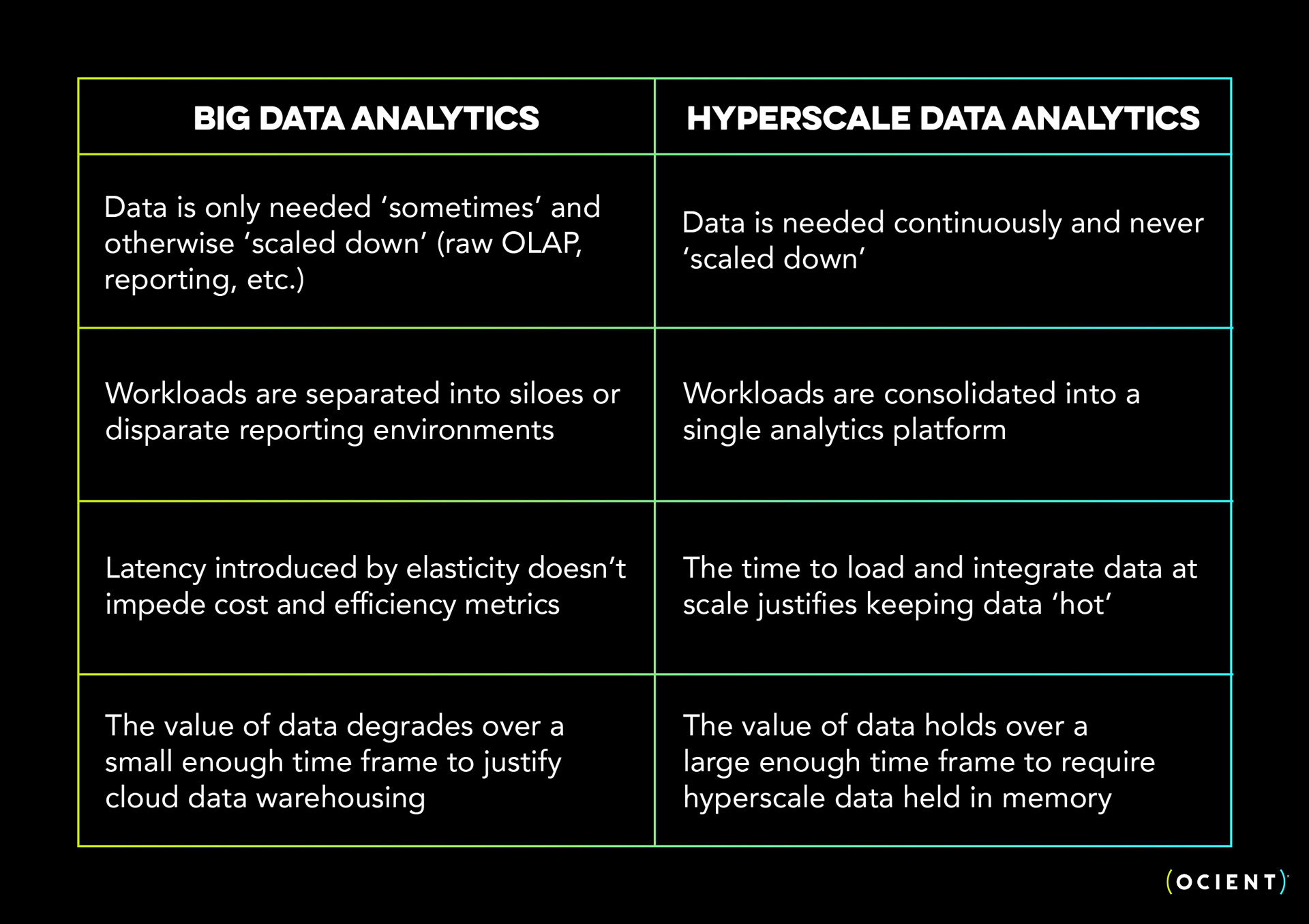
Understanding when you’ve hit “hyperscale”
One of the easiest ways to know when you’ve hit hyperscale requirements for your data and AI needs is when the amount of “hot” data you need to analyze becomes too expensive or difficult to manage in your existing cloud data warehouse, database, or lakehouse.
At Ocient, our specialty lies in hyperscale data analytics, machine learning, and geospatial data analytics. Whether you’re looking to consolidate existing workloads, leverage more of your growing data volumes, or lower the cost of processing complex data at scale, Ocient has been designed from the ground up for ultimate speed, performance, and efficiency.
We’re on a mission to streamline hyperscale data analytics but ultimately it doesn’t matter what we call it, it’s the value we unlock for our customers.. We want to work on your biggest data headaches and show capabilities that enable customers to activate data at a scale previously infeasible.
If you’d like to see Ocient in action, please get in touch to book a demo or talk with a member of our sales team.