
 By Jenna Boller, Senior Director of Marketing at Ocient
By Jenna Boller, Senior Director of Marketing at Ocient
In talking with customers about Ocient’s ability to streamline and consolidate the data and analytics stack across real-time analytics, OLAP data warehousing, in-database machine learning, always-on data integration, and more, I’ve recently been asked how our technology relates to the concepts of Data Mesh and Data Fabric. In the dynamic landscape of data management, both of these concepts have emerged in recent years, each promising to reshape the way organizations handle their data.
As businesses grapple with the complexities of big (and hyperscale) data, these approaches offer unique perspectives around handling data to weave it seamlessly across organizational operations in different ways. In this post, I’ll delve into the differences between Data Mesh and Data Fabric and explore how a data warehouse, specifically the Ocient Hyperscale Data Warehouse™, fits into both.
Data Mesh: Decentralized Data Paradigm
Coined by Zhamak Dehghani, the concept of a Data Mesh suggests shifting from a centralized data management approach driven by a central IT organization to a decentralized – domain-oriented – architecture in which each domain can create and add new data products to a mesh while consuming the data products built and shared by other domains.
What is Data Mesh?
Data Mesh is a decentralized approach to data architecture that aims to address the challenges of scaling data access and consumption across large organizations. As you can see in the diagram below, the data may be connected via governance and technology but each individual business unit can build domain specific architectures.
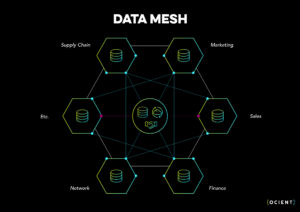
Key Principles of Data Mesh
- Data Ownership at the Domain Level: Each domain, such as Marketing, Sales, etc. seen in the example above, within an organization takes ownership of its data, fostering a sense of responsibility and accountability
- Data as a Product: Data is treated as a product with well-defined interfaces and service-level agreements (SLAs)
- Federated Computational Governance: Data products are governed by the domains that produce them, reducing the burden on centralized governance and democratizing the data engineering and pipeline development for each individual domain
The Role of a Data Warehouse in a Data Mesh Paradigm
Within a Data Mesh architectural framework, data warehouses operate as domain-specific data platforms. Each domain manages its own data warehouse(s), enabling autonomy and flexibility. This enables each domain to extract critical insights with more control and empowerment than would be possible within a centralized data management infrastructure.
For business units who have set preferences around the business rules and governance applied to leveraging data at the domain level, a Data Mesh architecture enables them to leverage the same data as other departments without abiding by a centralized set of business rules. Depending on the use case, this level of flexibility can offer significant benefits for business-level users and domain-specific data engineers.
Challenges of Data Mesh
Gartner predicts that by 2025, 80% of Data Mesh early adopters will fail to meet their planned SLAs around data engineering productivity, augmentation and federated governance. While data management at the domain level within a Data Mesh framework enables individual lines of business to operate flexibly within their own P&Ls, the overall cost of data engineering within an enterprise may be hard to track and manage effectively. Operating in siloes may lead to re-invention, inefficient use of the time and resources allocated at the department or business unit level, and the creation and storage of extra copies of data, which may negatively impact security and and scale costs across the business. Particularly where large amounts of data are leveraged in the cloud, a Data Mesh may drive up the cost of computing significantly.
Data Fabric: A Unified Data Ecosystem
Unlike Data Mesh, the concept of a Data Fabric revolves around creating a unified and integrated data ecosystem across an organization.
What is Data Fabric?
Data Fabric is an architectural paradigm that leverages unity and integration within a data ecosystem to seamlessly connect various data sources and repositories across an organization. As you can see in the diagram below, data is flowing through a centralized layer that is supported by governance functions such as metadata, data catalog, and security across the entire organization.
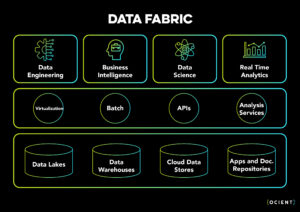
Key Principles of Data Fabric
- Unified Data Architecture: A Data Fabric creates a unified architecture that connects distributed data sources, such as data lakes, data warehouses, cloud stores and other document repositories as seen in the example above, enabling a consistent and comprehensive view of data
- Interoperability: Data Fabric emphasizes interoperability between different data systems via APIs, and other shared services, allowing for smooth data flow and integration
- Real-time Data Access: Data Fabric aims to provide real-time access to data, facilitating quicker decision-making
The Role of a Data Warehouse in a Data Fabric
In a Data Fabric architecture, data warehouses act as a central repository for integrated and transformed data. They play a crucial role in ensuring data consistency and observability, and in providing a unified view of the organization’s information. Within a Data Fabric framework, data warehouses must integrate with various data sources while managing queries and workloads across multiple lines of business and users. Any indication of a log jam or bottleneck undermines the goal of leveraging a unified platform approach to managing data across the organization.
Challenges of Data Fabric
While the concept of a Data Fabric supports the efficient and consistent use of computational resources and tools across an organization or enterprise, as data volumes scale, the ability to effectively scale data integration from a growing number of data pipelines, data analysis across multiple lines of business and users, and interoperability across various systems and tools may prove challenging. Any latency or lack of access to mission critical data may undermine the promise of a Data Fabric, and the cost of running in the cloud may get out of control as the volume of data movement within the Fabric grows.
Further, leveraging a Data Fabric requires the need to drive strong data governance across the entire organization, ensuring there is alignment around the adoption and enforcement of business rules at all levels and across all domains. Often times specific business areas want to use the same base data and apply very different business rules.
Choosing the Right Path Forward: How Ocient Supports Both Data Mesh and Data Fabric at Scale
While both Data Mesh and Data Fabric concepts address the goal of optimizing data management, they offer completely different approaches to tackling common challenges in scaling an organization’s ability to be more data-driven. Ultimately, the choice between these two architectures comes down to whether embracing decentralization or pursuing a unified data ecosystem will provide the best overall benefits for an organization.
The Ocient Hyperscale Data Warehouse™ enables organizations to establish a high-quality data foundation while accommodating the nuances of Data Mesh and Data Fabric architectures. The level of computing and resulting costs of executing both Data Mesh and Data Fabric frameworks will only scale overtime and become increasingly unpredictable as data volumes, data pipelines, and the number of data consumers grow.
Whether Ocient is supporting a specific department in a Data Mesh architecture ingesting and storing a voluminous data source for real time visibility or supporting many departments in a Data Fabric by integrating data from a variety of sources and providing robust OLAP capabilities, the platform can accommodate a wide variety of data and analytics needs.
Reduce the Cost of Data Engineering, Data Science, and Data Analytics at Scale
Ocient enables users to leverage both scale and performance while delivering predictable spend now and in the future. Unlike “pay as you go” cloud data warehouses, Ocient’s predictable pricing model enables users to gain maximum speed and performance across data integration (ETL), OLAP data warehousing, real-time analytics, and machine learning – all from a single platform.

Fuel Data Products and Consolidate More Workloads into a Single Platform
For high-intensity workloads with always-on data ingestion, transformation and analysis, Ocient can execute high levels of data processing at the domain level before delivering it to the Mesh. It can also handle the consolidation of multiple workloads into a single platform with workload management available to execute data ingest, analytics, and machine learning according to priority service classes and users. Data products and data marts can be built on top of Ocient, and multiple workloads can be executed at once, including hyperscale machine learning.
Leverage On Premises and Cloud Computing Ecosystems
Ocient enables users to leverage flexible deployment across on premises data centers and cloud computing ecosystems. Ocient’s hyperscale data warehousing software ultimately requires a standard bill of materials, ensuring there is no lock in for users now and in the future.
By building for both the Data Mesh and Data Fabric, Ocient brings the power of hyperscale data integration and analytics to a modern data management architecture and approach. Ocient can flex to support a line of business within a Data Mesh architecture by ingesting and storing a voluminous data source for real-time visibility and can also support multiple departments within a Data Fabric by integrating data from a variety of sources while providing robust OLAP, machine learning, and real-time analytics capabilities. To learn more about the Ocient Hyperscale Data Warehouse, download our overview paper.
For more information, or to see a demo of Ocient in action, get in touch today.